










How the Georgia Information Analytics Heart constructed a cloud analytics resolution from scratch with the AWS Information Lab
It is a visitor submit by Kanti Chalasani, Division Director at Georgia Information Analytics Heart (GDAC). GDAC is housed throughout the Georgia Workplace of Planning and Price range to facilitate ruled knowledge sharing between numerous state companies and departments.
The Workplace of Planning and Price range (OPB) established the Georgia Information Analytics Heart (GDAC) with the intent to supply knowledge accountability and transparency in Georgia. GDAC strives to assist the state’s authorities companies, tutorial establishments, researchers, and taxpayers with their knowledge wants. Georgia’s trendy knowledge analytics middle will assist to securely harvest, combine, anonymize, and combination knowledge.
On this submit, we share how GDAC created an analytics platform from scratch utilizing AWS companies and the way GDAC collaborated with the AWS Information Lab to speed up this mission from design to construct in file time. The pre-planning periods, technical immersions, pre-build periods, and post-build periods helped us give attention to our goals and tangible deliverables. We constructed a prototype with a contemporary knowledge structure and rapidly ingested further knowledge into the info lake and the info warehouse. The aim-built knowledge and analytics companies allowed us to rapidly ingest further knowledge and ship knowledge analytics dashboards. It was extraordinarily rewarding to formally launch the GDAC public web site inside solely 4 months.
A mix of clear path from OPB govt stakeholders, enter from the educated and pushed AWS workforce, and the GDAC workforce’s drive and dedication to studying performed an enormous function on this success story. GDAC’s associate companies helped tremendously by way of well timed knowledge supply, knowledge validation, and evaluation.
We had a two-tiered engagement with the AWS Information Lab. Within the first tier, we participated in a Design Lab to debate our near-to-long-term necessities and create a best-fit structure. We mentioned the professionals and cons of assorted companies that may assist us meet these necessities. We additionally had significant engagement with AWS material consultants from numerous AWS companies to dive deeper into the very best practices.
The Design Lab was adopted by a Construct Lab, the place we took a smaller cross part of the larger structure and applied a prototype in 4 days. In the course of the Construct Lab, we labored in GDAC AWS accounts, utilizing GDAC knowledge and GDAC sources. This not solely helped us construct the prototype, but in addition helped us achieve hands-on expertise in constructing it. This expertise additionally helped us higher preserve the product after we went reside. We have been capable of frequently construct on this hands-on expertise and share the data with different companies in Georgia.
Our Design and Construct Lab experiences are detailed under.
Step 1: Design Lab
We wished to face up a platform that may meet the info and analytics wants for the Georgia Information Analytics Heart (GDAC) and doubtlessly function a gold commonplace for different authorities companies in Georgia. Our goal with the AWS Information Design Lab was to provide you with an structure that meets preliminary knowledge wants and supplies ample scope for future growth, as our person base and knowledge quantity elevated. We wished every part of the structure to scale independently, with tighter controls on knowledge entry. Our goal was to allow simple exploration of information with sooner response occasions utilizing Tableau knowledge analytics in addition to construct knowledge capital for Georgia. This might enable us to empower our policymakers to make data-driven selections in a well timed method and permit State companies to share knowledge and definitions inside and throughout companies by way of knowledge governance. We additionally harassed on knowledge safety, classification, obfuscation, auditing, monitoring, logging, and compliance wants. We wished to make use of purpose-built instruments meant for specialised goals.
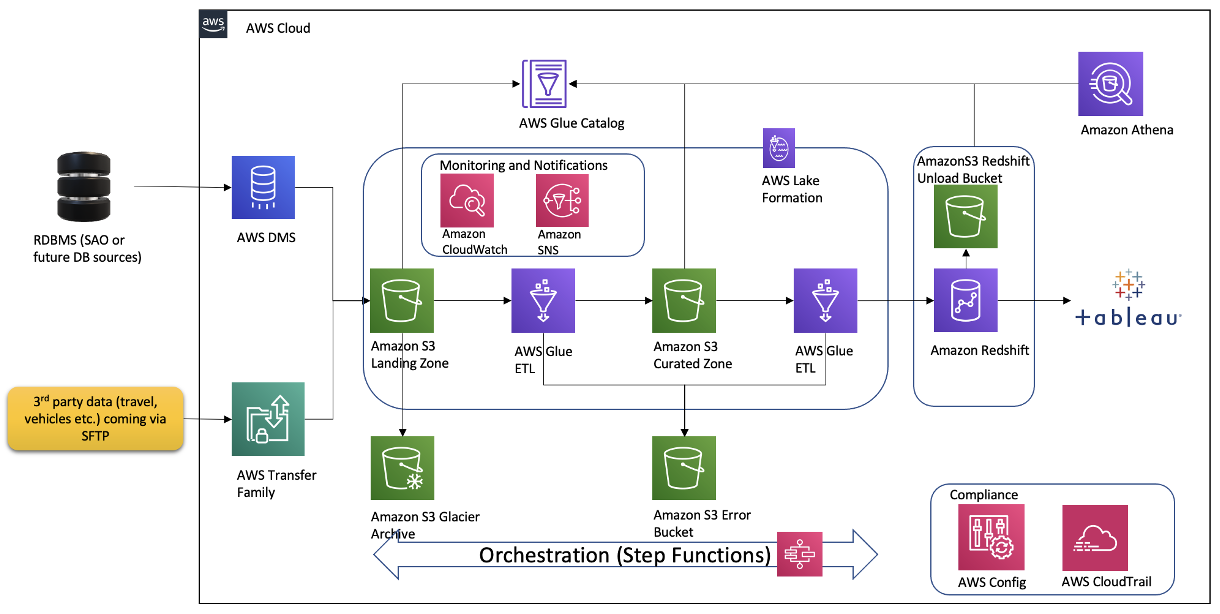
Over the course of the 2-day Design Lab, we outlined our total structure and picked a scaled-down model to discover. The next diagram illustrates the structure of our prototype.
The structure accommodates the next key parts:
- Amazon Easy Storage Service (Amazon S3) for uncooked knowledge touchdown and curated knowledge staging.
- AWS Glue for extract, remodel, and cargo (ETL) jobs to maneuver knowledge from the Amazon S3 touchdown zone to Amazon S3 curated zone in optimum format and format. We used an AWS Glue crawler to replace the AWS Glue Information Catalog.
- AWS Step Features for AWS Glue job orchestration.
- Amazon Athena as a strong instrument for a fast and intensive SQL knowledge evaluation and to construct a logical layer on the touchdown zone.
- Amazon Redshift to create a federated knowledge warehouse with conformed dimensions and star schemas for consumption by Tableau knowledge analytics.
Step 2: Pre-Construct Lab
We began with planning periods to construct foundational parts of our infrastructure: AWS accounts, Amazon Elastic Compute Cloud (Amazon EC2) cases, an Amazon Redshift cluster, a digital non-public cloud (VPC), route tables, safety teams, encryption keys, entry guidelines, web gateways, a bastion host, and extra. Moreover, we arrange AWS Identification and Entry Administration (IAM) roles and insurance policies, AWS Glue connections, dev endpoints, and notebooks. Recordsdata have been ingested through safe FTP, or from a database to Amazon S3 utilizing AWS Command Line Interface (AWS CLI). We crawled Amazon S3 through AWS Glue crawlers to construct Information Catalog schemas and tables for fast SQL entry in Athena.
The GDAC workforce participated in Immersion Days for coaching in AWS Glue, AWS Lake Formation, and Amazon Redshift in preparation for the Construct Lab.
We outlined the next because the success standards for the Construct Lab:
- Create ETL pipelines from supply (Amazon S3 uncooked) to focus on (Amazon Redshift). These ETL pipelines ought to create and cargo dimensions and information in Amazon Redshift.
- Have a mechanism to check the accuracy of the info loaded by way of our pipelines.
- Arrange Amazon Redshift in a personal subnet of a VPC, with applicable customers and roles recognized.
- Join from AWS Glue to Amazon S3 to Amazon Redshift with out going over the web.
- Arrange row-level filtering in Amazon Redshift primarily based on person login.
- Information pipelines orchestration utilizing Step Features.
- Construct and publish Tableau analytics with connections to our star schema in Amazon Redshift.
- Automate the deployment utilizing AWS CloudFormation.
- Arrange column-level safety for the info in Amazon S3 utilizing Lake Formation. This enables for differential entry to knowledge primarily based on person roles to customers utilizing each Athena and Amazon Redshift Spectrum.
Step 3: 4-day Construct Lab
Following a collection of implementation periods with our architect, we shaped the GDAC knowledge lake and arranged downstream knowledge pulls for the info warehouse with ruled knowledge entry. Information was ingested within the uncooked knowledge touchdown lake after which curated right into a staging lake, the place knowledge was compressed and partitioned in Parquet format.
It was empowering for us to construct PySpark Extract Rework Hundreds (ETL) AWS Glue jobs with our meticulous AWS Information Lab architect. We constructed reusable glue jobs for the info ingestion and curation utilizing the code snippets supplied. The times have been rigorous and lengthy, however we have been thrilled to see our centralized knowledge repository come into fruition so quickly. Cataloging knowledge and utilizing Athena queries proved to be a quick and cost-effective approach for knowledge exploration and knowledge wrangling.
The serverless orchestration with Step Features allowed us to place AWS Glue jobs right into a easy readable knowledge workflow. We hung out designing for efficiency and partitioning knowledge to attenuate value and enhance effectivity.
Database entry from Tableau and SQL Workbench/J have been arrange for my workforce. Our pleasure solely grew as we started constructing knowledge analytics and dashboards utilizing our dimensional knowledge fashions.
Step 4: Submit-Construct Lab
Throughout our post-Construct Lab session, we closed a number of free ends and constructed further AWS Glue jobs for preliminary and historic masses and append vs. overwrite methods. These methods have been picked primarily based on the character of the info in numerous tables. We returned for a second Construct Lab to work on constructing knowledge migration duties from Oracle Database through VPC peering, file processing utilizing AWS Glue DataBrew, and AWS CloudFormation for automated AWS Glue job era. When you have a workforce of 4–8 builders searching for a quick and simple basis for a whole knowledge analytics system, I might extremely advocate the AWS Information Lab.
Conclusion
All in all, with a really small workforce we have been capable of arrange a sustainable framework on AWS infrastructure with elastic scaling to deal with future capability with out compromising high quality. With this framework in place, we’re shifting quickly with new knowledge feeds. This might not have been potential with out the help of the AWS Information Lab workforce all through the mission lifecycle. With this fast win, we determined to maneuver ahead and construct AWS Management Tower with a number of accounts in our touchdown zone. We introduced in professionals to assist arrange infrastructure and knowledge compliance guardrails and safety insurance policies. We’re thrilled to repeatedly enhance our cloud infrastructure, companies and knowledge engineering processes. This sturdy preliminary basis has paved the pathway to infinite knowledge tasks in Georgia.
In regards to the Creator
 Kanti Chalasani serves because the Division Director for the Georgia Information Analytics Heart (GDAC) on the Workplace of Planning and Price range (OPB). Kanti is chargeable for GDAC’s knowledge administration, analytics, safety, compliance, and governance actions. She strives to work with state companies to enhance knowledge sharing, knowledge literacy, and knowledge high quality by way of this contemporary knowledge engineering platform. With over 26 years of expertise in IT administration, hands-on knowledge warehousing, and analytics expertise, she thrives for excellence.
Kanti Chalasani serves because the Division Director for the Georgia Information Analytics Heart (GDAC) on the Workplace of Planning and Price range (OPB). Kanti is chargeable for GDAC’s knowledge administration, analytics, safety, compliance, and governance actions. She strives to work with state companies to enhance knowledge sharing, knowledge literacy, and knowledge high quality by way of this contemporary knowledge engineering platform. With over 26 years of expertise in IT administration, hands-on knowledge warehousing, and analytics expertise, she thrives for excellence.
 Vishal Pathak is an AWS Information Lab Options Architect. Vishal works with clients on their use circumstances, architects options to resolve their enterprise issues, and helps them construct scalable prototypes. Previous to his journey with AWS, Vishal helped clients implement BI, knowledge warehousing, and knowledge lake tasks within the US and Australia.
Vishal Pathak is an AWS Information Lab Options Architect. Vishal works with clients on their use circumstances, architects options to resolve their enterprise issues, and helps them construct scalable prototypes. Previous to his journey with AWS, Vishal helped clients implement BI, knowledge warehousing, and knowledge lake tasks within the US and Australia.


